IMAGE FUSION: Law-enforcement needs create demand for image fusion
RICK S. BLUM
In recent years, image fusion has attracted increasing attention in a wide variety of applications such as concealed-weapon detection, remote sensing, intelligent robots, medical diagnosis, defect inspection, and military surveillance. Image fusion has drawn particular interest for applications in law enforcement that involve concealed-weapon detection, for which it appears that no single sensor technology can provide acceptable performance.
Image fusion has been in development at Lehigh University for the past 10 years under Department of Defense funding, through interactions with researchers at the United States Justice Department’s Center of Excellence for Law Enforcement Research at the U. S. Air Force Rome Laboratory in Rome, N.Y. Through the support of the United States Justice Department, police officers and law-enforcement experts were brought together to discuss their most pressing needs.
It was determined that what was needed was an intelligent system to automatically combine the outputs of sensors to detect metallic objects and to image the scene to show faces and the background. The resulting system produces one image that shows the most important aspects of a scene along with the presence of weapons.
Hardware and software
After several years of research we have determined that the best sensors in this case are a millimeter-wave sensor and a standard video camera. The millimeter-wave sensor is still relatively new but devices with reasonable performance are now becoming available.
Our research also led to a software package that enables automatic combination of images produced by several sensors to provide one image that summarizes the key information from all the source images. In fact, the package is very general and has been shown to be useful for applications other than concealed-weapon detection. If the source images come from different types of sensors and if these sensor types are carefully chosen, then the use of the different sensors along with image-fusion technology overcomes the limitations of each of the individual sensors. This approach is similar to that of the human body, which also makes use of multiple sensors to assess a given situation. The result is an overall system that helps a user make a valid decision in a relatively short period of time.
Application examples
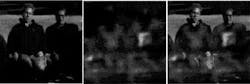
As an example of a concealed-weapons application, we have fused two images, one visual and the other at 94 GHz millimeter wave (MMW). The visual image provides the outline and the appearance of the people while the MMW image shows the existence of a gun (see Fig. 1).
As a second example, a multifocus image-fusion application can prove useful in enhancing digital-camera images (see Fig. 2). Inexpensive cameras can have difficulty obtaining images that are in focus throughout the scene, due to the limited depth-of-focus of the lenses used. To overcome this problem, we can take several images with different focal points and combine them together into a single composite image using image fusion. For further information on our research please see our laboratory website.1
Fusion algorithms
A simple image-fusion method involves taking the average of the source images, pixel by pixel. Along with simplicity come several undesired side-effects including reduced contrast, however. Most recently, many researchers recognized that multiscale transforms are very useful for analyzing the information content of images for the purpose of fusion. Multiscale representation of a signal was first studied by Rosenfeld, Witkin, and others.3, 4 Researchers such as Marr, Burt, and Adelson and Linderberg established that multiscale information can be useful in a number of image-processing applications.5, 6, 7
More recently, wavelet theory has emerged as a well developed yet rapidly expanding mathematical foundation for a class of multiscale representations. At the same time, some sophisticated image-fusion approaches based on the multiscale representations started to emerge and receive increased attention. Most of these approaches were based on the multiscale decomposition (MSD) of the source images (see Fig. 3).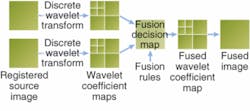
Many image-fusion algorithms have been proposed and we survey them elsewhere.2 However, these approaches have not been developed using a rigorous application of estimation theory, applied in such a way as to guarantee robustness (in a statistical sense). We have several “flavors” of our general approach. A simple version, which we call expectation-maximization (EM) fusion, is described below.
EM fusion
In this method, the true scene gives rise to a sensor image through a nonlinear mapping. We can approximate this mapping by a locally affine transformation. This transformation is defined at every coefficient of the multiresolution representation as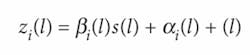
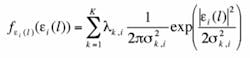
Using the expectation-maximization approach, we have developed a set of iterative equations that converge to maximum likelihood estimates of the model parameters. The processing structures that result, while developed using optimum statistical procedures, closely resemble those of radial basis function neural networks. Our optimum processing structures justify previously proposed processing structures and suggest some new ones that can greatly improve performance in some cases.
REFERENCES
1. www.eecs.lehigh.edu/SPCRL/spcrl.htm
2. R.S. Blum, Z. Liu, “Multi-Sensor Image Fusion and Its Applications,” published by CRC Press in the special series on Signal Processing and Communications (2006).
3. A. Rosenfeld, M. Thurston, IEEE Trans. Computers C-20, 562 (1971).
4. A. Witkin, J.M. Tenenbaum, “On the role of structure in vision,” in Human and Machine Vision, pp. 481-544, New York, Academic Press (1983).
5. D. Mart, Vision, San Francisco, CA; W.H. Freeman, 1982.
6. P.J. Burt, E. Adelson, IEEE Trans. Communications Com-31(4) 532 (1983).
7. T. Lindeberg, Scale-Space Theory in Computer Vision: Kluwer Academic Publisher (1994).
Rick S. Blum is a professor of electrical and computer engineering at Lehigh University, 19 Memorial Drive West, Bethlehem, PA 18015-3084; e-mail: [email protected]; www.eecs.lehigh.edu/SPCRL/spcrl.htm.