Deep learning brings a new dimension to machine vision
ANDREW WILSON
Many terms are now being used to describe what is, by some, being promoted as a revolution in machine vision, namely the ability for systems to analyze and classify objects without the need for computer programming. Artificial intelligence (AI) and deep learning are just two terminologies used to promote such concepts.
Underneath this hyperbole, however, describing the underlying science behind such concepts is more simple. In traditional machine vision systems, for example, it may be necessary to read a barcode on a part, judge its dimensions, or inspect it for flaws. To do so, systems integrators often use off-the-shelf software that offers standard tools that can be deployed to determine a data matrix code, for example, or caliper tools set using graphical user interfaces to measure part dimensions.
As such, the measurement of parts can be classified as good or bad, depending on whether they fit some pre-determined criteria. Unlike such measurement techniques, so-called “deep learning” tools are better categorized as image classifiers. Unlike software that specifically reads barcode data, they are designed to determine whether an object in an image is present or good or bad, for example. Hence, such tools are complementary.
“Deep learning tools such as neural networks will complement other machine vision techniques. For example, such a neural network could judge the probability that a data matrix code exists within an image,” says Arnaud Lina, Director of Research and Innovation at Matrox Imaging (Dorval, QC, Canada; www.matrox.com). “But to decode it, traditional barcode algorithms would be used.”
Classy operators
Neural network-based tools are often used to determine part presence or whether an object in an image is good or bad. These tools belong to a group of algorithms known as image classifiers, ranging from instance-based classifiers such as k-nearest neighbor (k-NN) to decision-tree classifiers. A chart showing different types of classifiers can be found at “A Tour of Machine Learning Algorithms,” by Jason Brownlee, November 2013; http://bit.ly/VSD-TMLA).
A number of these can be used in machine vision applications. Companies such as MVTec Software (Munich, Germany; www.mvtec.com) already offer pre-trained neural networks, support vector machines (SVM), Gaussian mixture models (GMM) and k-NN classifiers in its HALCON software package. It should be noted that deep learning network training from scratch requires several hundreds of thousands of sample images for each error class to achieve valid recognition results. HALCON, however, comes integrated with extensive deep learning networks. Thus, only relatively few sample images are needed for the training, saving significant time and money.
Companies such as Stemmer Imaging (Puchheim, Germany; www.stemmerimaging.com) also use SVMs in its Common Vision Blox (CVB) Manto software.
When the feature values of different groups significantly overlap, an SVM can be used to generate a multi-dimensional feature space to isolate different defect groups. Many such classifiers are offered by PR Sys Design (Delft, Netherlands; http://perclass.com) in its perClass software. This features a range of classifiers such as k-NN, neural networks, Random Forests, and SVMs. The image analysis software is a MATLAB-based toolbox that allows developers to interactively work with data, choose the best features within the data for image classification, train the numerous types of classifiers and optimize their performance (see “Machine learning leverages image classification techniques”, Vision Systems Design, February 2015; http://bit.ly/VSD-MLL).
Emulating the brain
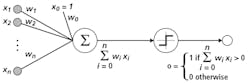
Just as a number of different classifiers can be used to discern objects within images, numerous types of neural networks exist that can be deployed to perform image classification functions. Such neural networks attempt to emulate biological neural networks used in the human visual system and brain. The simplest of these is the Perceptron invented in 1957 by Frank Rosenblatt (see Fig. 1).
The Perceptron models the neurons in the brain by taking a set of binary inputs (nearby neurons), multiplying each input by a continuous valued weight (the synapse strength to each nearby neuron), and thresholding the sum of these weighted inputs to output a “1” if the sum is big enough and otherwise a “0” in a similar fashion that biological neurons either fire or not (see “A ‘Brief’ History of Neural Nets and Deep Learning,” by Andrey Kurenkov (http://bit.ly/VSD-NNDL).
Today, more sophisticated networks use two or more layers of such “neurons” to perform image classification tasks. These “hidden layers” can find features within image data presented to the neural networks. Numerous neural network architectures ranging from the simple Perceptron, to Deep Feed Forward (DFF) and convolutional neural networks (CNN), can be used in applications like handwriting analysis and speech recognition (see “The mostly complete chart of Neural Networks, explained” by Andrew Tch (http://bit.ly/VSD-CCNN).
The CNN is, perhaps, the most widely adopted neural network deployed in machine vision systems. Several reasons exist for this. First, the CNN’s architecture is designed to emulate more closely that of the human visual cortex and pattern recognition mechanisms. This is possible because the CNN is divided into several neuronal stages that perform different functions (see Fig. 2).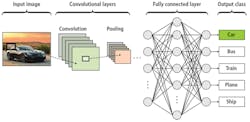
In this simplified figure, both the convolutional and pooling layers are shown separately for illustrative purposes. In practice, they form part of the complete CNN. In CNNs, convolutional layers are used to perform feature extraction, just as convolution operators are used to find features such as edges.
In conventional image processing, image filters such as Gaussian blurring and median filtering can be offloaded to field-programmable gate arrays (FPGA) to perform this task.
CNN architectures, on the other hand, emulate the human visual system (HVS) where the retinal output performs feature extraction such as edge detection. In CNNs, this convolution serves to perform feature extraction, and thus represent features of the input images. These convolutional layers are arranged into feature maps where each neuron has a receptive field, connected to neurons in the previous layer via a set of trainable weights used to determine the type of filter that may be applied.
After such features are extracted, so-called “pooling layers” are used to reduce the spatial size of the representation of image data to increase computational speed. This image data is then fed to a final network layer for further data processing (see “Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review” by Waseem Rawat and Zenghui Wang, Neural Computation, Volume 29, Issue 9, September 2017; http://bit.ly/VSD-DCNN).
No programming required
Neural networks do not require conventional or FPGA programming techniques as other approaches do. Instead, CNNs can be trained to recognize objects in three different ways. In the first—supervised learning—images are manually labeled and, using this data, an output model is generated that classifies unknown images. While supervised learning requires tagging image data, unsupervised learning methods can find patterns in image data and build models from multiple unknown images. Then, by interpreting these results, a more accurate supervised classifier can be developed.
Such unsupervised learning systems are often inaccurate and may benefit from semi-supervised learning techniques that incorporate labeled data to reduce the number of images that need to be trained.
“Regarding these different approaches, most of our tools are based on supervised training,” says Michał Czardybon, General Manager at Adaptive Vision (Gliwice, Poland; www.adaptive-vision.com). “This is most effective since it is not necessary to design algorithms manually. However, there is a need to provide labeled training data. One of our tools, Anomaly Detection, uses a semi-supervised method in which the developer provides a number of ‘good’ images of objects, and the network is trained only to recognize any deviations from these.”
“For those who would like such software to operate in unsupervised mode,” says Czardybon, “our technology is not yet ready. However, we are further researching semi-supervised learning where a small number of labeled samples are accompanied with hundreds of unlabeled samples to improve accuracy.”
In building such networks, developers can turn to both commercially available and open source development tools. While commercially-available tools such as Version 11 from Wolfram (Long Hanborough, Oxfordshire, England; www.wolfram.com), the Deep Learning Toolbox from MathWorks (Natick, MA; www.mathworks.com) and Neural Designer from Artelnics (Salamanca, Spain; www.artelnics.com) can be used to develop neural network-based applications, other companies offer open-source code to perform this task (see “Deep Learning Software”; http://bit.ly/VSD-DLS and “Comparison of deep learning software”; http://bit.ly/VSD-CDLS).
Open source solutions
Large companies such as Intel (Santa Clara, CA, www.intel.com), IBM (Armonk, NY; www.ibm.com), NVIDIA (Santa Clara, CA; www.nvidia.com), Microsoft (Redmond, WA; www.microsoft.com) and Google (Mountain View, CA; www.google.com) all offer open-source code to develop machine learning algorithms.
Interestingly, Keras (https://keras.io), a developer of a high-level neural network application programming interface (API) written in Python, has shown in a chart comparing deep learning frameworks based on eleven data sources that Google’s TensorFlow machine learning library is the most widely adopted machine learning software (see Fig. 3).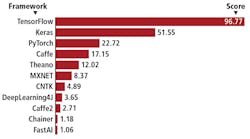
While Keras provides a high-level interface, it does not handle low-level operations, according to François Chollet, the founder of Keras. Rather, these are performed by open-source code from Google’s TensorFlow or Theano (http://deeplearning.net/software/theano), an open-source project developed at the Montréal Institute for Learning Algorithms (MILA) at the Université de Montréal (Montréal, QC, Canada; www.umontreal.ca).
Using these tools, developers are deploying vision-based applications. Intel, for one, has demonstrated the use of its OpenVINO toolkit in partnership with Philips (Amsterdam, Netherlands; www.philips.com) in a system that performs deep-learning inferences on X-rays and computed tomography (CT) scans without using GPUs. Such analysis could take hours or days using general purpose CPUs.
To extend the performance of existing CPU architectures, Philips deployed the OpenVINO toolkit and deep learning methods to provide almost a 200X speed increase over a standard CPU approach for deep learning, obviating the need to use GPUs. However, it is not only in medical imaging where such tools are being deployed. In this video (http://bit.ly/VSD-OV), Jeff McAllister, a Senior Technical Consulting Software Engineer at Intel, shows how the OpenVINO toolkit can be used in machine vision applications.
Targeting machine vision
With all these development tools available it’s no wonder that numerous machine vision companies are introducing products that often use these toolkits in the development of software specifically targeted at machine vision applications. Although reticent to discuss which tools may be used or whether other classification tools are also used in their products, these companies offer a way for developers to evaluate the potential of neural networks in machine vision.
Numerous examples now exist showing how such software packages have been deployed. At YuMei Die Casting (Chongqing, China; http://yumei.cqrfym.com), for example, the company has deployed Intel’s Joint Edge Computing Platform in a system based on Intel’s computer vision and deep learning software to detect defects as parts are cast.
Realizing the power of such approaches, Cognex (Natick, MA; www.cognex.com) purchased ViDi Systems (Villaz-Saint-Pierre, Switzerland) and its ViDi software suite in 2017. Recently, the software was deployed by AIS Technologies Group (Windsor, ON, Canada; www.aistechgroup.com) in a cylinder bore inspection system (see “Smart vision system ensures 100% cylinder bore inspection,” Vision Systems Design, March 2018; http://bit.ly/VSD-3DBI).
Another company, d-fine (Frankfurt, Germany; www.d-fine.com) has developed a system for Seidenader Maschinenbau (Markt Schwaben, Germany; www.seidenader.de/en/home) to test the performance of CNNs in systems to inspect medical products. Results are now being analyzed to compare the effectiveness of such methods with traditional machine vision approaches (see “Medical Products Inspected with Deep Neural Networks;” http://bit.ly/VSD-MPDL).
A prolific proponent of such technology has been Cyth Systems (San Diego, CA; www.cyth.com), a company that has its own AI-based software called Neural Vision. This software has been used in a range of applications, from semiconductor lead frame inspection (http://bit.ly/VSD-NVFI), medical device inspection (http://bit.ly/VSD-CNV) and robotic pick-and-place systems (http://bit.ly/VSD-CPAI; see Fig. 4).
Cameras capture the net
Although many systems deploy such software on PC-based systems, camera vendors are realizing the opportunity of offering smart cameras able to perform the task. These include IDS Imaging Development Systems (IDS; Obersulm, Germany; https://en.ids-imaging.com) and FLIR Systems (Richmond, BC, Canada; www.flir.com/mv).
Using a specially-developed AI vision application, IDS’ NXT camera can be used to load pre-trained artificial neural networks while FPGA-based AI acceleration increases inference times. At VISION 2018, the camera was demonstrated as an AI-based object recognition system. Also introduced at show, FLIR’s FireFly integrates Intel’s Movidius Myriad 2 vision processing unit (VPU) onto which trained neural networks can be directly loaded.
With such announcements, smart cameras will run traditional machine vision algorithms and neural network-based classifiers, giving developers flexibility in the algorithms they use. Driving this will likely be open-source code from companies like Google, Intel, and Microsoft, which will be leveraged by commercial imaging software developers to bring such products to market much faster.
ACKNOWLEDGEMENT
This article was first published in the April 2019 issue of Vision Systems Design.
Andrew Wilson (1956–2019) was the founding editor of Vision Systems Design magazine, as well as an industry authority and author of thousands of technical articles on image processing, machine vision, and computer science.